
A Guide for Data Science Projects in 2023
Published:
This post explains how to define a problem statement and perform the necessary tasks to achieve meaningful results. It provides a walkthrough of a structured approach to ensure the successful completion of a data science project.  —
—
How to Start?
Find/Define a Problem Statement
The problem statement is a critical first step in any data science project. It provides a clear definition of the problem to be solved and guides the development of research questions and hypotheses toward a well-defined solution.
How to Find the Scope of the Problem and Where to Begin?
One approach to start and solve any case scenario is to use the following method and structure a solution accordingly:
- Clarify:
- Define the scope of the problem.
- Constrain:
- Refine the problem by setting boundaries and parameters.
- Plan:
- Frame your response.
- Identify data gathering solutions.
- Explore collaboration opportunities if needed.
- Plan statistical analyses to be implemented.
- Method:
- Perform Data Quality Inspection and Exploratory Data Analysis (EDA).
- Conduct data preprocessing and feature engineering, including:
- Data Cleaning, Data Integration, Data Transformation, and Data Reduction.
- Implement feature selection methodologies.
- Create and evaluate models, including hyperparameter tuning.
- Visualize results.
- Deploy the model.
- Conclude:
- Provide conclusions by explaining the problem statement’s significance.
- Recommend decisions based on results.
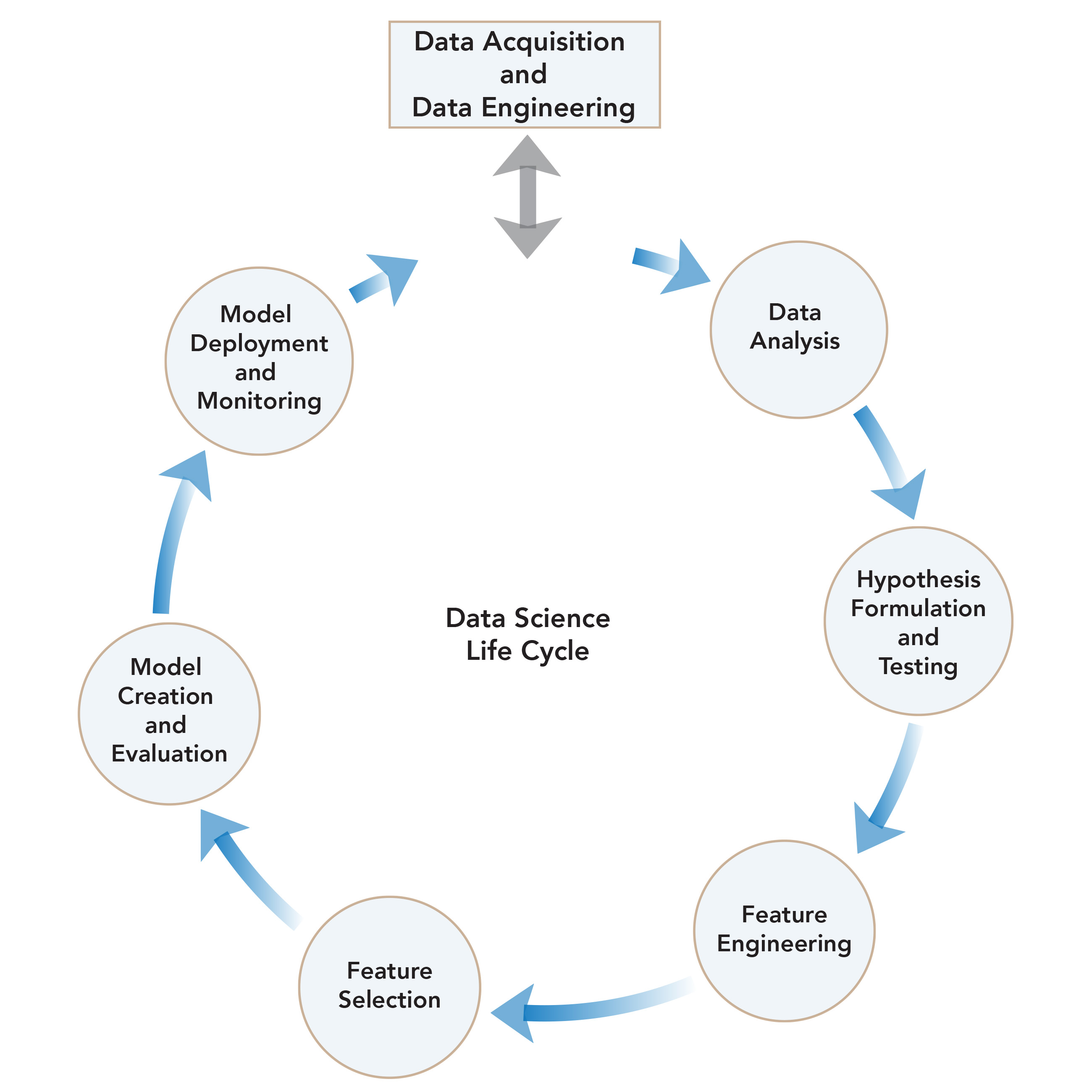
Stages Involved in Solving a Typical Data Science Problem
The links provided below are crucial for obtaining detailed explanations and deeper understanding of the concepts mentioned.
Data Science Workflow
Links to Key Stages
1. Data Analysis
2. Hypothesis Formulation and Testing
3. Feature Engineering
Perform appropriate data analysis to obtain a meaningful set of attributes.
4. Feature Selection
5. Model Creation and Evaluation
6. Model Deployment
Deploy the trained model for corresponding use-case scenarios. Monitor and retrain the model as necessary.
- Local Deployment:
- Frameworks: Streamlit, Django, Flask, Express.JS
- Cloud Deployment:
- Platforms: AWS, GCP, Microsoft Azure
- Containerization:
- Tools: Docker, Kubernetes
- Using APIs:
- Frameworks: Flask, Express.JS, FastAPI
Prerequisites for Solving Problems
1. Python Programming Language

2. Statistics

3. Databases


4. Visualization Tools

References
Textbooks:
- Introduction to Algorithms for Data Mining and Machine Learning (Xin-She Yang)
- Introduction to Statistical Learning
- Making Sense of Data II: A Practical Guide to Data Visualization, Advanced Data Mining Methods, and Applications
- Data Science Interview Guide ACE-PREP